Feedback loop from Logging and Monitoring to User Stories
Feedback loop from Logging and Monitoring to User Stories Link to heading
Using the Dashing app to tie our current monitoring and logging data back to original user stories and close the loop### Intro Link to heading
During my presentation last month I went through how we find issues in the services using our monitoring and logging platforms to track down specific cases.
This information is useful when we have problems. How about when we want to better understand our users and fulfil their stories?
These solutions are seen from the point of view of the service and not from our original use case.
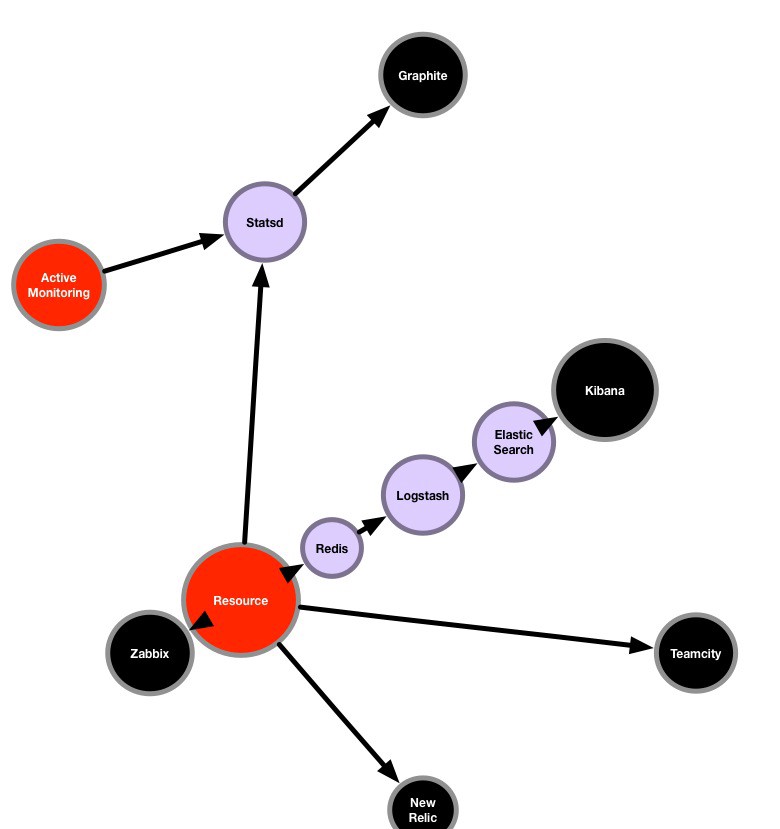
Current Monitoring and Logging
All these interfaces shown in black are representations of the same service but in metrics like uptime and error rate we remove the original user experience.
For this we’re testing Dashing. With it we can run jobs that collect information from our monitoring and logging and re-build a single user experience independently from the streaming stack.
Thanks to the real time logging we randomly pick a stream done in the last minute and grab all information around the user. With our monitoring we can guess what kind of TTFB the user had.
Examples Link to heading
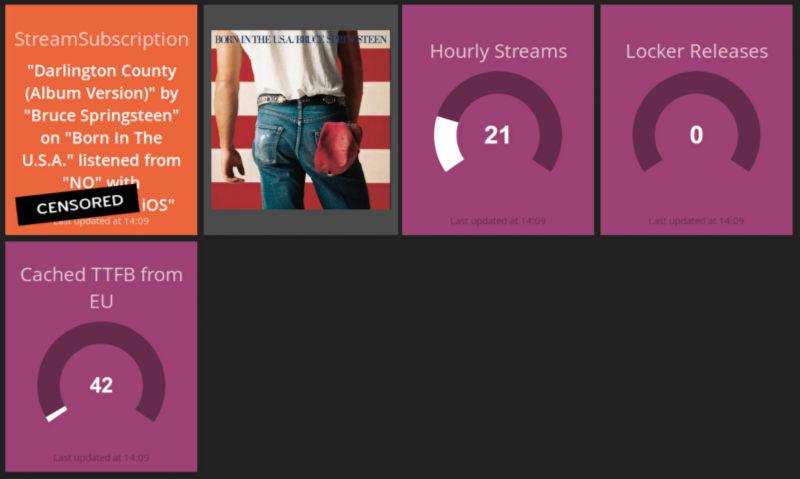
Subscription example
Above Dashing shows a single stream occurred that in the last minute, we can re-build it as such:
Given a **user**``**With a subscription**``When streaming from **Norway**``With **an iOS device**``Then start streaming a track in less than **100ms**
We have a concrete example of a track, location, TTFB and the user’s experience represented by number of purchased tracks (locker) and number of tracks streamed in the last hour.
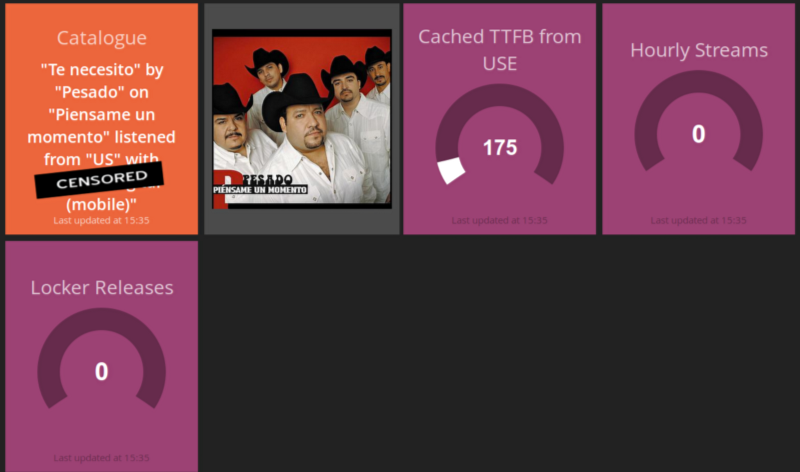
Radio example
The stream is picked randomly independent of type of stream and customer as we’re only looking for the end user experience. In the above example we know there is a mobile radio from the US and we try to guess the TTFB from the US East Coast.

Locker example
Yet another example above of a random user in Great Britain streaming tracks that were purchased.
Results Link to heading
There are quite a few advantages of adding this to our stack.
We’re brought back from where we see everything as a service and forget about the individual user.
We can find new use cases that were missed from user stories, for example, do a lot of subscription users also purchase tracks?
And we bring the different solutions together by joining the results of the monitoring solution with the logging solution.
Next Link to heading
One of the problems with the current implementation is that TTFB is a guess, although these are done through active monitoring they only represent the speed from EC2 in the availability area closest to the example.
In the future we’d rather get this data from the actual user and get it pushed anonymously back to us so we can have real TTFB and differentiate between providers, types of mobile connection, countries/states and more to further improve the experience.
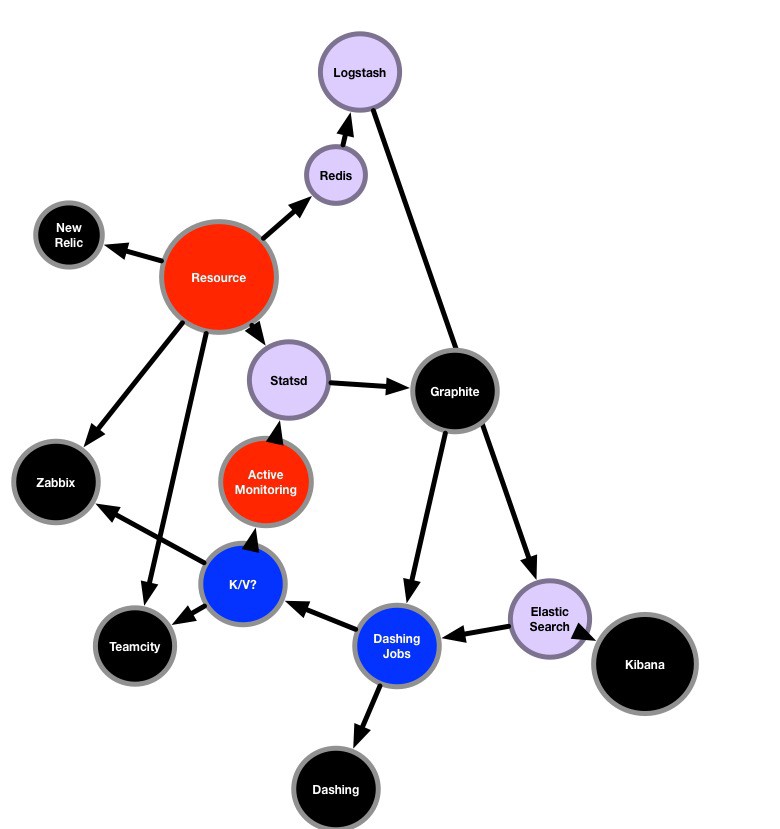
Another idea was to push the streams picked by Dashing and return them to the monitoring platforms so the test monitoring data is based on a sample of the latest streams.
Unfortunately Dashing does not offer a read API so this would have to be done by some sort of store for the values (represented above as K/V?) to be fed back.
This would allow us to join all the different solutions and close the loop by having the monitoring adapt to the most streamed tracks instead of only a subset of tracks picked by the team.