Icecast in Production (Devops Weekly #248)
A few months ago I was asked to help out with an independent online radio — The radio had reached the limit of their current infrastructure and had lost their previous contractors.
History Link to heading
The radio started organically as a project between friends from their flat in London. From there they rented a local studio and set up a business broadband.
They expanded to a few hundred listeners until the traffic was too much for their studio connection. Everything was done at the same place — Streaming through Icecast and play-listing through Airtime.
A new server on Rackspace with Icecast so the radio didn’t struggle with the studio connection and had room for more listeners. Other formats were also added with Liquidsoap. Airtime was still kept in the studio and was connected to Icecast manually.
I was contacted at the last minute as they had reached the maximum of concurrent users from that server and had broken contact with the previous contractors.
The first look around Link to heading
I was given access to their Rackspace account — There were no SSH keys left with the radio (they didn’t know what that was) and there were no functioning backups! My first steps were to re-activate the backups and clone the current Production instance to log in and see if it worked as expected.

Nero watching Rome burn
I got copies of all the configurations and replaced the Production instance right away with the clone once I had tested it manually as I had no control or access to the other instance. It was a hard choice to switch Production with that little knowledge but the random streaming problems from that blackbox were worse.
I generated the clone with a larger instance size as I assumed the increasing problems were due to the number of users.
I also added New Relic right away to monitor the front-end, available metrics and some useful user information.
Initial observations Link to heading
The most obvious problems were Liquidsoap creating high CPU load to generate new formats in real time and bandwidth for that server. These were both solved instantly with the larger instance which allowed me to work without firefighting Production.
After a few days studying user requests I noticed that barely any alternative formats were used and started phasing out barely used formats which would create lag in the connection.
When Icecast sees the source lagging too far behind it starts to cut when it reaches max buffer size creating ‘hiccups’ in the audio.
The other big problem was that Rackspace has a poor cost/bandwidth relation compared to competitors.
Automation Link to heading
I started reverse engineering the Production instance by using Chef/Test-Kitchen to create local instances and adding tests to it.
I used AWS to generate new instances on a Pre-Production environment with Opsworks (Chef). I used Codeship to run the tests and S3 as an artefact repository.
Codeship
Even though the bandwidth/cost of AWS instances is better than Rackspace for similar sizes I only used this configuration as I was already familiar with it
Other extras were added like an NGINX reverse proxy on the instances, logging, monitoring, better security and updates and more.
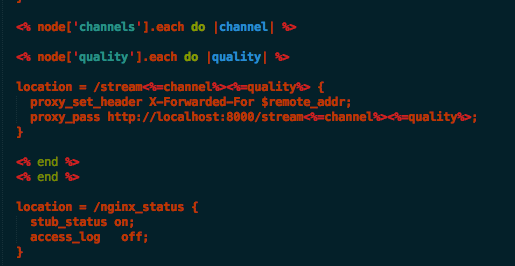
NGINX reverse proxy for different formats, also NGINX NewRelic Plugin
The NGINX proxy allows me to handle host headers, response headers, add monitoring and other useful behaviours which are not standardised on Icecast.
Icecast Architecture Link to heading
Studying the Icecast documentation we can find a Relay-Master architecturewhere one of the instances (Master) focuses on receiving the studio or Airtime connection and is open for listeners. While the Relay type instances behave like listeners that then relay its audio to a larger number of listeners.
The Master can also run LiquidSoap and not have as many CPU issues as the number of listeners is reduced to the total number of Relays.
First production release Link to heading
Checking several providers I found that the best cost/bandwidth result was with DigitalOcean which give a flat 1TB transfer for $5. Even though the flat transfer amount does not increase incrementally with the size of the instances I went around it by generating several Relay instances.
This not only gave me cheap transfer rates but also allowed me to generate instances in different geo location to improve TTFB and allow region failover.
I ran these instances using Knife Bootstrap with Knife Solo and kept an AWS instance on the side as a Canary, this allowed me to auto-scale Relays on AWS if there was an emergency and make sure the whole processes worked on both providers.

I used round-robin DNS with health checks per region to make sure all traffic was going to all the relays and I could have one or more relays out at any time without urgency.
On top of those is a geo DNS that will send the user to the closest available region. Each region also fails over to the other ones.
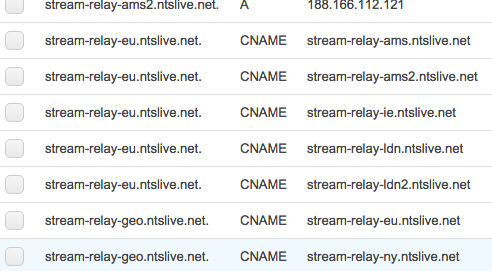
Route53
The idea being if a whole region like America goes down it will fail over to Europe (very useful as seen with AWS downtime).
After bringing several Relays up I replaced the current DNS entry for streaming with the global geo DNS name taking out all user traffic from the old Production instance.

New Relic NGINX plugin with active and dropped connections
This allowed me to have about ten times more concurrent users with a fifth of the previous cost of one instance on Rackspace thanks to the reduced transfer charges.
New Airtime. Link to heading
Airtime was also moved to a new provider using S3 to keep all current audio so it can still be used if there are problems at the studio and enforcing a backup of all shows on S3.
New Master Link to heading
After having all the relays in Production I focused on automating the Master instance.
The biggest changes were on the actual source failover in the master which now had three sources as priority.
The first one is the studio which connects to the Icecast Master. In case of studio being switched off or having issues it will fail-over to a second studio (this is a mobile studio mostly used for guests).
In case the second studio is offline it will failover to the new Airtime. Now using Airtime with 24h of content it allows to fail over to previous content in case of connection problems from the studio — without the need for a manual switchover.
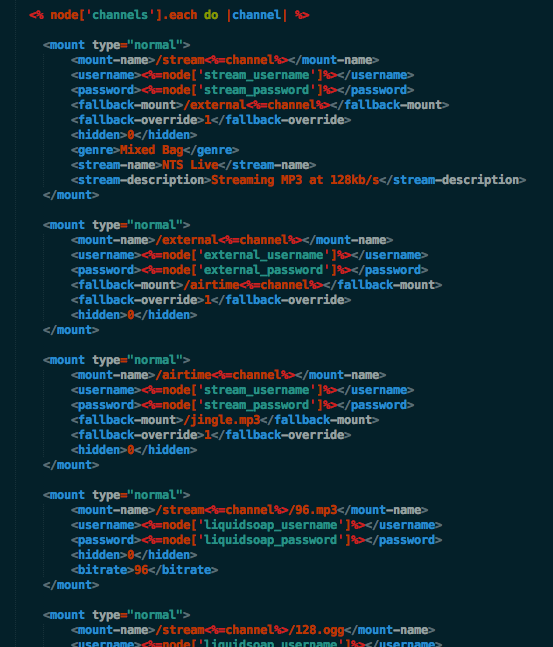
Icecast Relay configuration on Chef
Several fail-over tests were done pre-Production to ensure Relays would switch between the old Master and the new automated Master instance.
A copy of Master with no traffic was also added to fail-over if there’s any downtime with the Master instance but there is the problem that all Relays need to restart Icecast to bind to the new IP.
The actual move between the Master instances was done in off peak hours around 5am to ensure the minimum number of listeners and any unknown unknowns from the old Master instance.
Master on Opsworks and ‘Canary’ Relay
I’m still not completely happy with the way Masters are setup as it is still a single point of failure and you might have to scale one out vertically. Although a Master can handle hundreds to thousands of Relays and you can even scale it even further by adding another tier of Relays.
Another way in the future to scale it out horizontally would be to separate different channels onto different Masters.
Results Link to heading
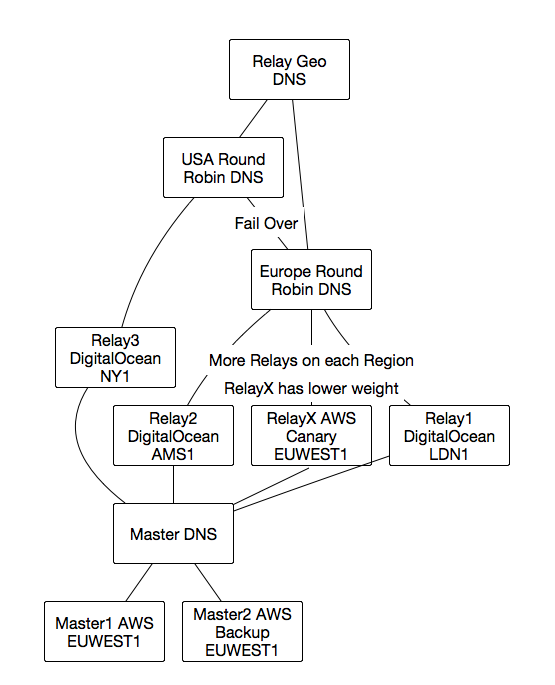
Icecast Diagram
The new streaming architecture is much more reliable than the previous one.
It is much more configurable and readable using its automation as documentation and the continuous integration process allows me to be sure that the creation or update of a new Relay or Master will work with all current features.
I was also able to provide an architecture that handles ten times more traffic for a small part of the cost and is highly scalable horizontally.
The metrics and monitoring also allowed me to tweak the platform to the actual user needs by adding Relays closer to users in the US whose TTFB is now under 200ms from several seconds to connect to the EU master.
Also to have leaner instances by removing unnecessary formats in Liquidsoap.
Current round-robin/health checks on DNS allows me to have a degraded performance and not worry about the whole streaming going out as well as realtime alerts.
The whole process took about a month.